7주차 복기
1. OpenAPI 활용한 기상청 데이터 분석
수업을 따라 들으며 코드를 작성하는 것도 바쁘지만, 지나고 나면 "오타 없이 쳤다"라는 만족감 외에 남는 게 없기 때문에, 매번 전체 과정을 통합한 과제가 필요하다는 생각을 했다. 때마침 시각화 수업 마지막에 강사님께서 수업 내용 전반을 다룬 퀴즈를 내주셨다. Chat GPT 도움 없이 스스로 해냈다는 뿌듯함을 갖고, 잊지 않기 위한 복기를 시작한다.
<Quiz>
step 1. 기상청 일자료 조회서비스에서 open API를 활용, 2022년~2023 데이터를 csv, xlsx로 수집한다. (변경가능)
step 2. 수집한 데이터를 데이터베이스에 적재한다 (splite, postgres, mysql, oracle)
step 3. 적재한 데이터베이스를 DB api를 활용해 데이터 가지고 온다.
step 4. 가지고 온 데이터를 활용해 그래프를 최소 3개 이상 시각화한다.
<해석 과정>
1) STEP 1.
- 2023년 현재까지 데이터 요청. 하지만 2022년 1개년 데이터를 보는 것이 좋을 것 같아서 2022년만 가져온다.
- api 가져와서 분석하기 위해서는 requests, pandas 모듈 필요
- url 가져올 때 base, end point를 나눠서 가져올 것인지, params로 가져올 것인지 결정 -> 그냥 url로 가져온다.
* params 방식이 많이 쓰여서, 연습 필요
- request 했을 때, 응답 코드가 200 나옴 -> 여기서 애를 먹었는데, 요청값이 데이터프레임으로 잘 안 보였음
* json_data.keys() : 가지고 온 데이터의 키값을 보여줌, 그 값에서 단계적으로 내려가면서 필요한 부분을 선택
* df.to_csv('저장 파일명', index=False, encoding='utf-8-sig') : 데이터프레임 형태를 csv로 저장

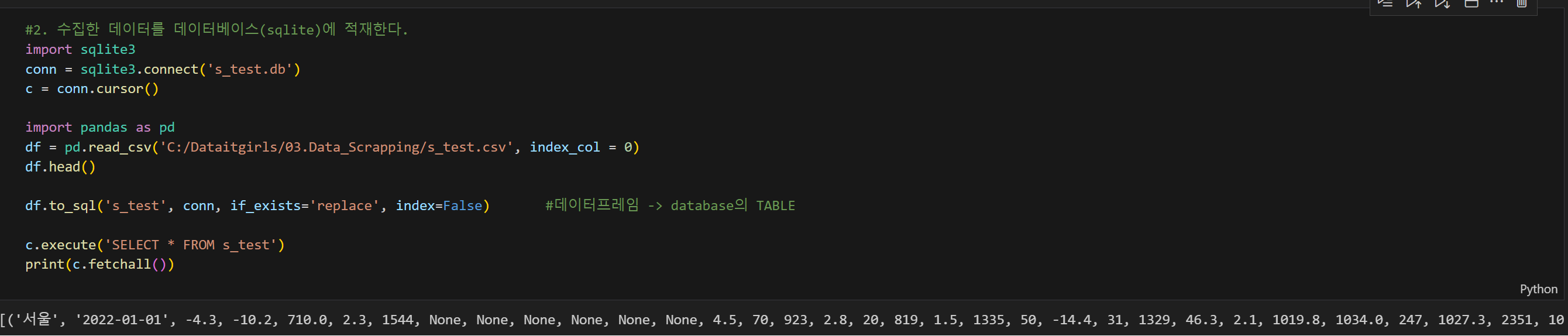
2) STEP 2.
- sqlite에 접속하기 위해서 connect 객체와 cursor를 사용한다. sqlite3 모듈 설치, conn, cursor까지 기본
- 수집한 csv 파일 경로를 불러와 df.head()로 데이터프레임을 확인하고 to_sql 베이터베이스의 테이블 형태로 보낸다.
- 데이터베이스 연결객체 'c'를 사용해서 query를 작성하고, c.fetchall() 함수로 쿼리문을 가져온다
- 경로 저장할 때 '\' 형태는 '/'로 변경해야 오류가 안남
3) STEP 3.
- DB API를 활용해 데이터를 가져오는 것은 현업에서 굉장히 많이 쓰이는 과정(이라고 하심)
- 쿼리 데이터 출력했는데 칼럼명이 없을 때, 칼럼을 확인해 넣어주기 위해서는 c.description과 for문 사용

<클라우드 데이터베이스 연결>
- df = pd.read_sql(f'select * from aapl', con)
- sql 쿼리를 짠 후 connection 객체를 만들어서, read_sql로 데이터를 가지고 온 다음에 분석을 시작

4) STEP 4.
- matplotlib, seaborn, plotly 라이브러리 중에서, seaborn을 사용해 보기로 함 (matplotlib 근본, plotly Interactive 라이브러리)
- 데이터프레임이 아닌, 일단 csv 파일로 접근해 보기로 함. 과거 현업에서 파일형태 요청이 더 많았던 것 같아서 파일로 도전.
- pandas, seaborn, plt 모듈을 설치하고, 파일 저장 경로에서 불러옴
- 2022년 일자별 데이터를 groupby 활용해 월별 평균을 도출할 생각을 함.
- 이전에 to_datetime 문자열을 날짜 형태로 변환해야 함
- 월까지 추가하기 위해 dt.strftime("Y-%m) 매써드 사용해 형태 변경
- barplot(월별 최고 평균기온 추이) : 뻔한 결괏값이지만, 문자열을 날짜 형식으로 변경하는데 의의가 있었음
- lineplot(월별 평균 강수량) : 연속형과 범주형의 그래프를 그려보고 싶었음. 2022년은 6월, 8월, 10월, 3월 순으로 비가 많이 옴
- scatterplot(기온과 지면온도의 관계) : 완벽한 상관성이 있는지 확인해보고 싶었음. 환경문제로 궁금했는데, 양의 상관관계 성립






2. 파이썬 데이터 시각화
<이론>
1) 데이터 베이스를 설계하여 수집한 데이터를 넣고, DB API 활용해 데이터를 가지고 오는 것 = 현업 활용도 높음
2) 시각화 : 연속형(시간, 날짜 등)과 범주형(학년, 반 등)을 파악하여, 변수 간의 관계가 비교, 관계, 추세, 분포를 비교한다.
3) 탐색적 데이터분석 : 데이터 탐색하고, 데이터의 패턴, 관계, 특징을 이해. 잠재적인 문제나 가설을 발견 (구조파악, 시계열 데이터분석, 변수간 상관관계 등 분석의 종류가 있다) → 분석기법 : 집중화경향(평균, 중앙값, 최대 최솟값), 분산도(표준편차, 사분위) 파악
figure vs. axes vs. axis
1) figure : 그림 전체를 나타내는 객체 (=도화지)
2) axes : 그래프 그리는 영역
3) axis : x축과 y축
Matplotlib
1) x = np.arange(100, 300, 10) y = np.random.randn(20) # 데이터를 배열 형태로 넣어야 한다.
2) import matplotlib.pyplot as plt #matplotlib 설치
3) plt.figure(figsize=(15, 5)) #default (figsize=(6.4, 4.8)) inch # figure 사이즈 키우기
4) fig, axes = plt.subplots(3, 1, figsize = (15,10)) #그래프 그릴 때 fig랑 axes를 먼저 그리고 시작하기
5) plt.hist(mpg['cty']) #모듈.그래프명(파일명['칼럼'])
6) mpg['fl'].unique() #파일명['칼럼'].unique() -> 유니크한 값을 보고, 그래프를 선택할 수도 있다.
Seaborn
1) import seaborn as sns #seaborn 모듈 설치
2) mpg = pd.read_csv('파일 경로') #데이터프레임 불러오기
3) sns.scatterplot(data = mpg, x = 'displ', y = 'hwy') #배열로 넣지 않고 데이터를 바로 넣을 수 있다.
4) sns.scatterplot(data = mpg, x = 'displ', y = 'hwy', hue = 'drv') #hue를 쓰면 범례와 범례별 색이 구분된다.
5) 시각화하기 전에 데이터 그룹 후 정렬하기
mpg.groupby('drv').mean() #groupby 해준다 -> 오류가 나오는 이유는 문자열 포함
mean_drv = mpg[['drv','hwy']].groupby('drv').mean() #필요한 부분만 문자열로 추출
mean_drv = mpg[['drv','hwy']].groupby('drv', as_index = False).mean() #인덱스로 되어있으니 빠진다.
sort_mean_drv = mean_drv.sort_values(by = 'hwy', ascending= False) # groupby 이후 내림차순
6) sns.barplot(data = sort_mean_drv, x= 'drv', y='hwy', order = ['r', '4', 'f']) #order을 넣어서 순서를 정해줄 수 있다
7) 데이터 프레임과 시리즈
type(mpg['manufacturer']) #데이터타입 series, 칼럼은 1개 #괄호가 하나면 시리즈
mpg['manufacturer', 'model'] #2개 이상의 칼럼을 확인하고 싶을 때, series 1개의 데이터타입만 안 받기 때문에 2개 선택 못함
mpg[['manufacturer', 'model']] #여러 개를 받으려면 데이터프레임 # 괄호가 두 개면 데이터프레임
8) 문제 풀이 과정 : suv 차종을 대상으로 cty 평균이 가장 높은 회사 5개 출력
mpg['category'].unique() #카테고리 확인
mpg['category'] == 'suv' #SUV카테고리로 묶는다
suv_mpg = mpg[mpg['category'] == 'suv'] #한번 더 감싸줘서 데이터프레임 출력
mean_suv_mpg = suv_mpg[['manufacturer', 'cty']].groupby('manufacturer', as_index = False).mean() #그룹으로 묶어준 후 출력
top5_suv_manufacturer = mean_suv_mpg.sort_values(by = 'cty', ascending = False).head(5) #내림차순 후 5개만 출력
sns.barplot(data = top5_suv_manufacturer, x = 'manufacturer', y = 'cty')
Plotly
1) 리스트 형태로 넣을 수 있고, 데이터프레임 형태로도 넣을 수 있다.
2) import plotly.express as px #plotly 모듈 설치
3) fig = px.scatter(mpg, x="displ", y="hwy") #스캐터차트
4) fig = px.scatter(mpg, x="displ", y="hwy", color="drv", symbol="drv") #seaborn에서는 hue -> color
5) fig = px.bar(sort_mean_drv, x='drv', y='hwy', color = 'drv') #막대그리프 #컬러로 구분
6) fig = px.violin(mpg, y="displ", color="fl", violinmode='overlay') #바이올린 차트
7) sns.violinplot(data=mpg, x="fl", y="displ") #seaborn으로 바이올린 차트 그리는 것
8) fig = px.line(economics, x="date2", y="unemploy") #라인차트
9) fig = px.box(mpg, x="drv", y="hwy", color = "drv") #박스플롯
3. 클라우드 데이터베이스(ElephantSQL) 연결 후 데이터베이스 만들기
1. https://www.elephantsql.com/ 접속, 가입 후 create new instance 생성
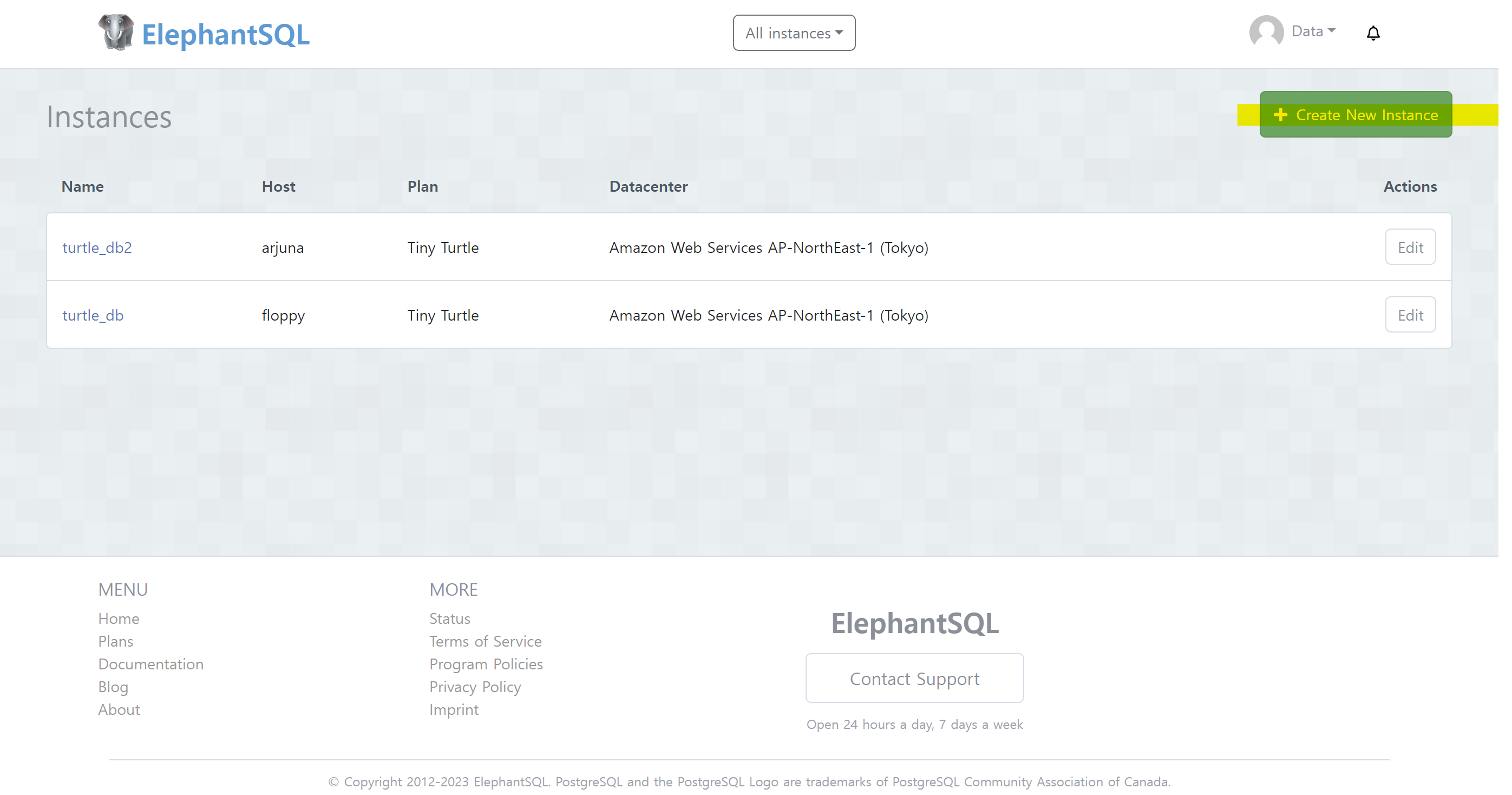
2. 제목 임의 생성하기

3. data center - tokyo 선택 (korea 없음)

4. 새로운 instance 생성 확인

5. 생성 후 details 확인하여 host, database, password, port 확인

6. DBeaver에서 좌측 콘센트(+) 클릭 -> elephantSQL 확인 -> connect to a database 창에서 값 입력

7. 생성 확인
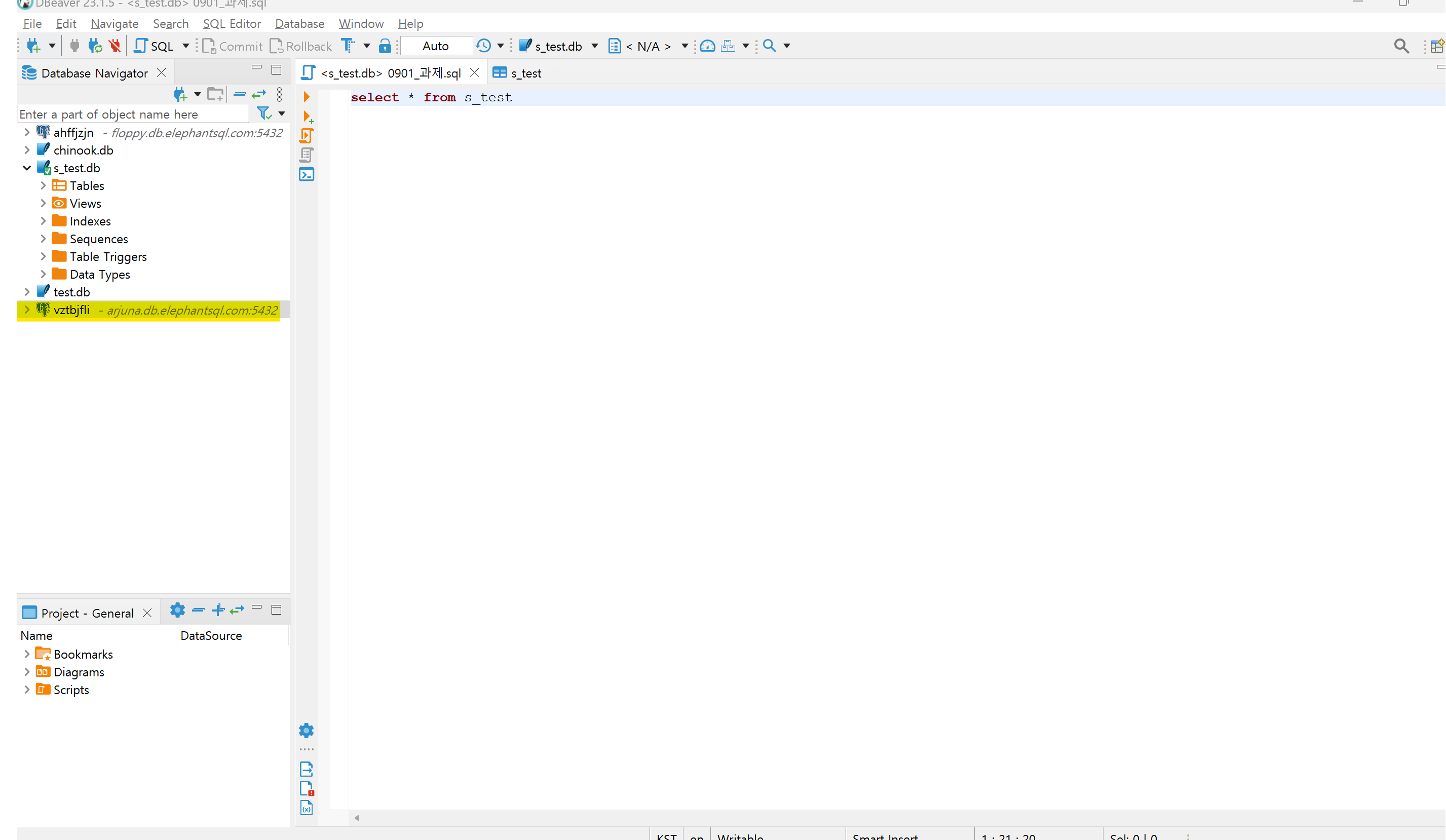
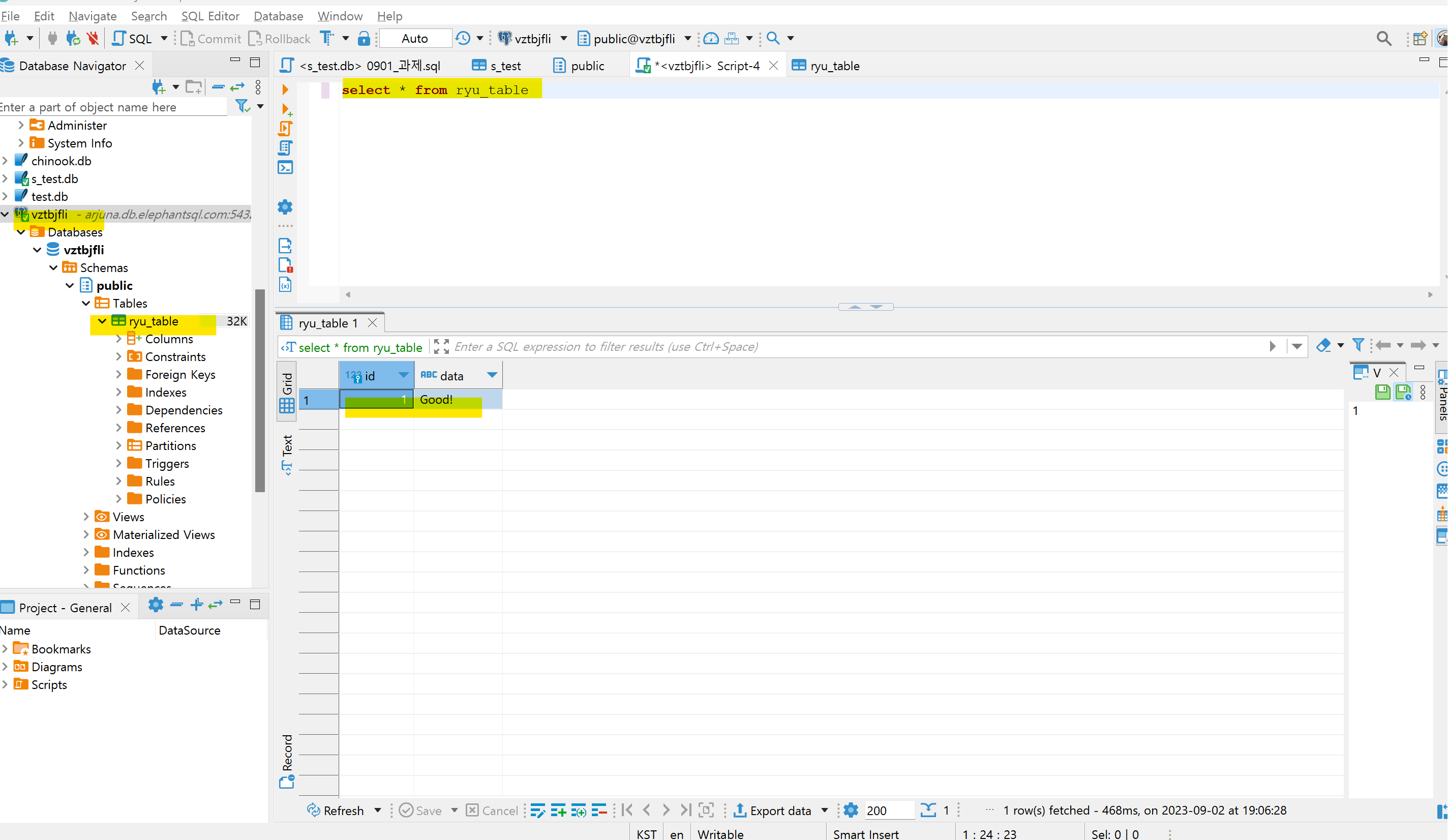
8. ipynb에서 데이터베이스 입력 -> 연결 닫힘 결과출력 *except와 finally은 연결 오류 방지를 위해 코드 입력

9. SQLite에서 테이블 생성 확인
4. 한 주의 마무리
1) 쾌적한 환경에서 효율적인 스터디를 위해 데스크를 구매했다.
2) 수면 부족으로 카페인 섭취를 늘렸는데, 대체 음료를 찾아봐야겠다.
3) 데이터 시각화를 할 때, 전체 맥락을 보고 접근 필요!